
Word2vec与GloVe在线学习比较
1.概念理解
Word2vec和GloVe都是用于生成词嵌入的算法,它们可以根据词汇的共现信息,将词汇编码成一个向量。这两种模型的主要区别在于它们的训练方式和损失函数的设计。
2.训练方式
Word2vec是一种“predictive”的模型,它要么根据上下文预测中间的词汇,要么根据中间的词汇预测上下文。相比之下,GloVe是“countbased”的模型,它的训练过程是对真值做了改变和对损失函数的推导过程。
3.损失函数
Word2vec的损失函数通常是交叉熵损失,而GloVe的损失函数则是基于共现矩阵的元素构建的,其中包含了词汇i和j共同出现的次数。GloVe的损失函数还包括一个加权函数f,用于避免只学习到常见词的词向量模型。
4.优缺点比较
Word2vec是局部语料库训练的,其特征提取是基于预测上下文或中间词的方式。这种方式优点是能够捕捉到词与词之间的局部关系,但缺点是没有考虑到词序信息以及全局的统计信息。而GloVe则是基于全局预料,结合了LSA和word2vec的优点,能够更好地捕捉到单词之间的语义特性,如相似性和类比性。
5.应用场景
Word2vec和GloVe都广泛应用于自然语言处理任务中,如文本分类、情感分析等。它们都能够提供高质量的词向量,但具体选择哪种模型,还需要根据实际任务的需求和数据情况来决定。
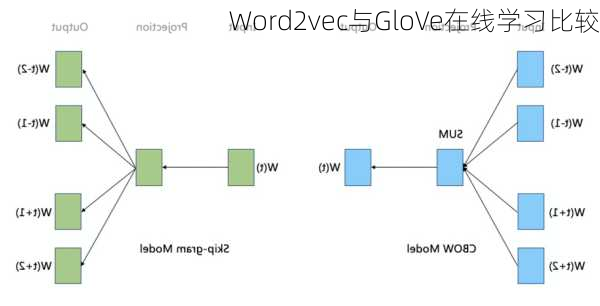
总的来说,Word2vec和GloVe都是非常有效的词嵌入模型,它们各有优缺点,在线学习比较是一个复杂的话题,需要根据具体的应用场景和需求来综合考虑。







