
LOF算法如何识别异常值
1.LOF算法的基本原理LOF(Local
Outlier
Factor),即局部异常因子,是一种基于密度的异常检测算法。它的基本思想是,如果一个数据点周围的数据点很密集,那么这个数据点很可能是一个正常数据点;相反,如果一个数据点周围的数据点很稀疏,那么这个数据点很可能是一个异常数据点。这是因为异常数据点往往远离正常数据点的密集区域。
2.LOF算法的密度定义在LOF算法中,密度是通过数据点之间的距离来计算的。具体来说,对于一个数据点,如果它到其他数据点的距离越远,那么该数据点的密度就越低;如果它到其他数据点的距离越近,那么该数据点的密度就越高。
3.LOF算法的计算流程LOF算法的计算流程可以分为以下几个步骤:
计算Kdistance:对于距离数据点P最近的几个点中,第k个最近的点跟点P之间的距离称为点P的K邻近距离,记为Kdistance(p)。计算可达距离:可达距离是基于K邻近距离和数据点P与点O之间的直接距离的最大值。
计算局部可达密度:数据点P的局部可达密度就是基于P的最近邻的平均可达距离的倒数。距离越大,密度越小。
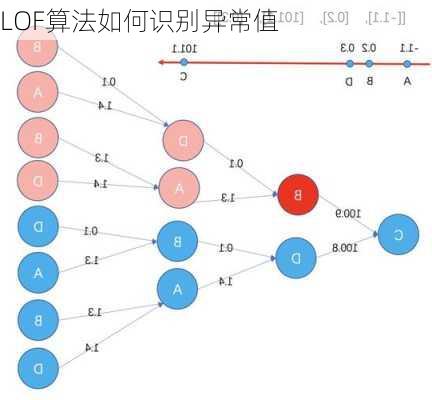
计算局部异常因子:数据点p的局部异常因子(局部离群因子)为点p邻域内点的平均局部可达密度跟数据点p的局部可达密度的比值。如果一个数据点的局部异常因子LOF值越大,说明它越可能是一个异常数据点;如果LOF值接近于1,则认为它是正常数据点。4.LOF算法的应用场景
LOF算法适用于中等高维的数据集,当数据集中存在不同密度的不同集群时,LOF算法表现良好。它在许多领域都有应用,例如电子商务中的犯罪活动检测、罕见实例发现等。
总的来说,LOF算法通过比较每个数据点与其邻域内其他数据点的密度来识别异常值。如果一个数据点的密度远低于其邻域内的其他数据点,那么它就被认为是一个异常值。







