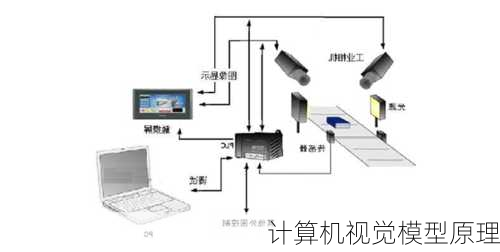
计算机视觉模型原理
计算机视觉是一门多学科交叉的科学,涉及计算机科学、电子工程、自动控制、心理学、哲学等多个领域。其目的是让计算机能够“看”到并理解周围的环境,从而实现对图像和视频的处理和分析。以下是计算机视觉模型的一些基本原理。
1.图像在计算机中的表示
在计算机中,图像被表示为一个三维数组,每个元素代表图像中的一个像素点,包含了该位置的亮度(灰度图像)或颜色信息(彩色图像)。这些信息通常以RGB值的形式存在,每层分别代表红、绿、蓝三个颜色通道的亮度值。
2.计算机视觉的基本任务
计算机视觉的主要任务是识别出图像中的对象及其特征,如形状、纹理、颜色、大小、空间排列等,从而尽可能完整地描述该图像。这包括图像分类、目标检测、目标识别等任务。
3.计算机视觉的算法
计算机视觉领域有许多重要的算法,如RANSAC(随机一致性采样)算法。RANSAC是一种用于在含有噪声数据的情况下拟合模型的算法,特别适用于估计本质矩阵或基本矩阵等计算机视觉任务中的模型。
4.计算机视觉的模型架构
在计算机视觉模型中,Attention机制是一个重要的组成部分。Attention机制允许模型在处理图像时聚焦于图像的特定区域,增强了模型对图像细节的关注度。这种机制有助于提高模型的性能,并且符合人脑和人眼的感知机制。
5.计算机视觉的应用
计算机视觉技术在多个行业中得到了广泛应用,如零售、医疗、制造业和自动驾驶等。在零售业,计算机视觉被用于顾客行为分析、商品推荐和防***机制。在医疗领域,计算机视觉用于医学图像处理,帮助医生进行疾病诊断。在自动驾驶汽车中,计算机视觉技术用于识别道路、车辆和行人等对象。
综上所述,计算机视觉模型原理涉及到了图像的表示、基本任务的执行、关键算法的应用以及在各种行业中的实际应用等多个方面。随着深度学习技术的发展,计算机视觉模型的表现能力不断提升,为人们的生活带来了更多的便利和智能化体验。