
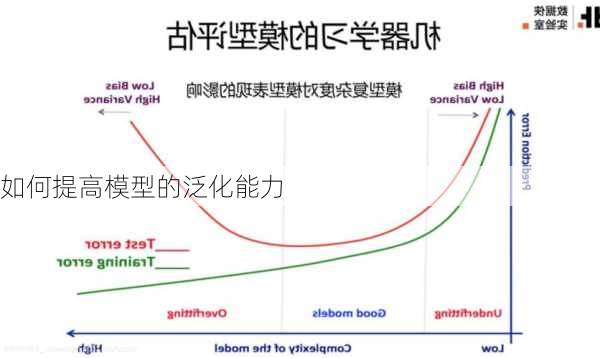
如何提高模型的泛化能力
提高模型的泛化能力是机器学习和深度学习中的一个重要课题。泛化能力指的是模型对未曾见过的数据的适应能力,也就是模型举一反三的能力。以下是提高模型泛化能力的一些方法:
1.数据集增强
数据集增强是一种有效的方法,可以通过人为增加数据集中的样本数量来提高模型的泛化能力。例如,对于图像数据,一些常用的数据增强技术有旋转、翻转、裁剪,以及添加噪声等,通过这些操作人为增加训练数据多样性,而不需要收集更多的样本。
2.特征工程
特征工程是通过对数据进行预处理和特征选择,来提高模型的泛化能力。深度学习中的这个过程可以通过深度神经网络自动完成,学习到数据内部的模式和结构。
3.正则化技术
正则化是一种常用的泛化技术,通过直接改变模型的架构来解决过拟合问题,从而改进训练过程。例如,L2正则化通过在损失函数中添加L2惩罚项,鼓励更小的权重并防止模型过拟合。
4.Dropout
Dropout是一种在训练过程中随机禁用一部分神经元的方法,防止对特定神经元的依赖,提高模型的鲁棒性和泛化能力。
5.Batch
Normalization
Batch
Normalization通过在每个小批量的训练数据中对输入进行标准化,来应对模型训练过程梯度消失和爆炸问题,并且可以在一定程度上减轻过拟合。
6.学习率衰减
学习率衰减是一种有效的提高模型泛化能力的方法,它可以在训练过程中逐渐降低学习率,帮助模型更好地收敛。
7.数据预处理
数据预处理包括数据清洗、数据增强、特征工程等,这些方法可以帮助模型更好地理解和学习数据,从而提高模型的泛化能力。
8.模型结构调整
通过简化模型参数或者加入L2正则化对参数进行惩罚,也可以采用丢弃法泛化误差不会随着训练数据集里的样本数量增加儿增大,所以通常选择大一些的训练数据集。
以上方法都可以有效地提高模型的泛化能力。在实际应用中,可以根据具体的问题和数据来选择合适的方法。







